Sequence Display enables large-scale sequence–activity datasets for rapid protein evolution
映射适应度景观:“序列展示”技术通过大规模基因型-表型记录加速蛋白质进化
开发具有特定功能的蛋白质历来是一项艰巨的任务,通常需要多轮劳动密集型的定向进化(DE)和筛选。虽然噬菌体展示等高通量选择方法简化了高适应度变体的分离过程,但它们往往忽略了更广泛的序列-活性景观,特别是对于训练鲁棒机器学习(ML)模型至关重要的低活性变体。在《自然-生物技术》(Nature Biotechnology)的一篇论文中,研究人员展示了“序列展示”(Sequence Display)平台,该平台能在单次实验中生成大规模、高质量的蛋白质序列-活性数据集,有效弥合了实验生物学与预测模型之间的鸿沟。
序列展示的作用机制
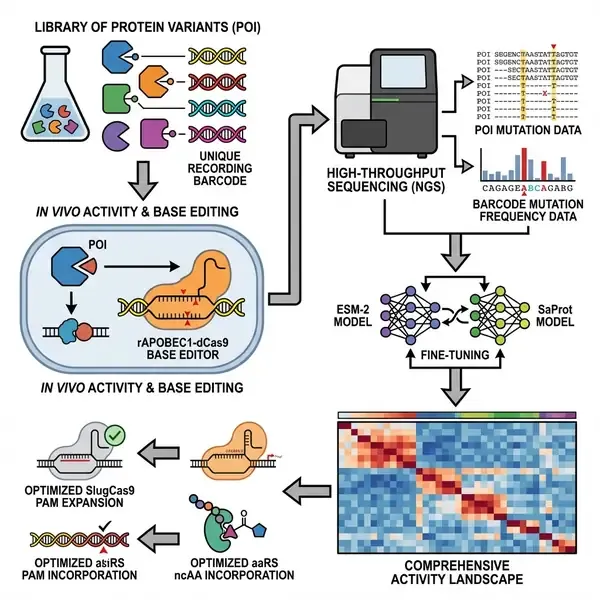
“序列展示”的核心创新在于其能够将蛋白质变体的生物活性转化为永久的遗传记录。该平台在编码目标蛋白(POI)的序列相邻处引入了一个记录条形码。每个POI变体的活性与一个碱基编辑系统耦合,该系统以活性依赖的方式在条形码区域引入突变。因此,条形码内C到T的突变频率直接反映了该变体的功能表现。通过利用二代测序(NGS)同时读取POI的基因型及其相关的条形码表型,研究人员可以在1到3天内生成包含数百万个数据点的数据集。
扩大紧凑型Cas9的靶向范围
研究人员通过进化路登凯撒葡萄球菌Cas9(SlugCas9)展示了该平台的实用性。SlugCas9是一种紧凑型核酸酶(1,054个氨基酸),适用于单腺相关病毒(AAV)递送,但受限于其严格的NNGG原间隔序列临近基序(PAM)。利用多重条形码系统,研究人员同时评估了SlugCas9变体对四种不同PAM(NNGA、NNGT、NNGC和NNGG)的活性。
通过将生成的序列-活性数据与预训练蛋白质语言模型(pLMs,如ESM-2和SaProt)相结合,团队构建了精细的活性景观。这种机器学习驱动的方法识别出了几种高性能变体,其中最显著的是SlugCas9-ADVTR。该变体在哺乳动物细胞中对所有四种NNGN PAM均表现出显著增强的编辑效率,优于野生型酶以及此前通过噬菌体辅助进化获得的变体(如SlugCas9-RRRSKI)。PAM识别范围的扩大显著提升了紧凑型Cas9工具在治疗应用中的基因组靶向范围。
工程化氨酰-tRNA合成酶以实现遗传密码扩充
除了核酸酶,“序列展示”还被应用于进化氨酰-tRNA合成酶(aaRS),特别是巴氏产甲烷八叠球菌PylRS(IPYE)。其目标是增强对模拟赖氨酸翻译后修饰的非天然氨基酸(ncAAs)的整合能力,如丙酰赖氨酸(PrK)、丁酰赖氨酸(BuK)和乙酰赖氨酸(AcK)。
该平台成功识别出了具有卓越整合效率的aaRS变体。例如,变体MbPylRS(IPYE)-LFLT对AcK和PrK的活性显著提高。这些结果强调了该平台在工程化复杂酶功能方面的通用性,以及其推动遗传密码扩充领域发展的潜力。
科学价值与未来展望
“序列展示”的意义超出了本研究中进化的特定蛋白质。通过提供一种可扩展的方法来获取全面的数据集(包括高活性和低活性变体),该平台解决了机器学习引导的蛋白质工程中的主要瓶颈:缺乏高分辨率的训练数据。研究表明,随着训练数据集规模从100个点增加到16,000个点,pLM模型的预测准确性呈指数级提高。
尽管该系统目前依赖于合成基因盒的设计来将活性与碱基编辑耦合,但其在单次运行中映射超过1000万个数据点的能力代表了范式的转变。“序列展示”为快速发现优化蛋白质提供了一个强大的框架,有望加速生物技术、合成生物学和精准医学的发展。