Single-molecule peptide sequencing through reverse translation of peptides into DNA
分子生物学的中心法则描述了从DNA到蛋白质的信息单向流动。尽管DNA和RNA测序已达到单分子灵敏度和大规模并行化,但蛋白质组学的发展相对滞后,这主要是由于蛋白质缺乏扩增机制以及20种氨基酸组成的复杂性。在《自然·生物技术》(Nature Biotechnology)发表的一项里程碑式研究中,研究人员提出了一种“逆翻译”策略,有效地将多肽测序转化为DNA测序问题。通过将氨基酸迭代转化为带有DNA条形码的报告分子,该平台实现了具有单氨基酸分辨率和高通量的单分子多肽测序。
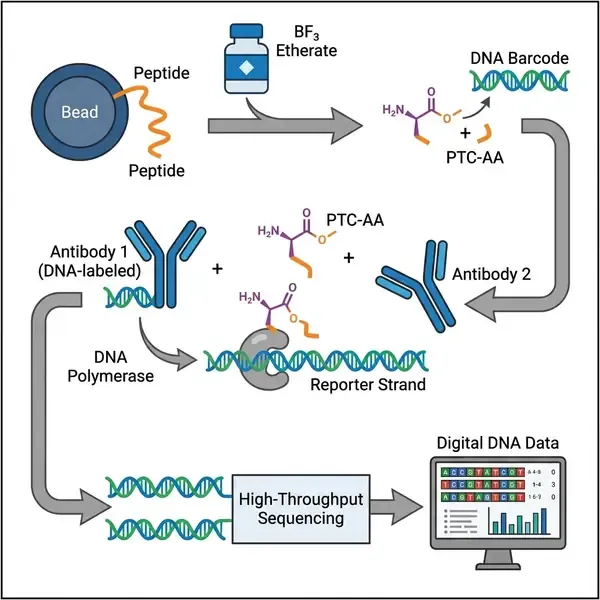
这一创新的核心是一个三阶段的分子过程。首先,团队开发了DNA兼容版的Edman降解法。传统的Edman降解使用三氟乙酸(TFA),这会导致DNA发生灾难性的脱嘌呤。为了规避这一问题,研究人员在乙腈中使用三氟化硼乙醚(BF3 etherate),并用抗酸的7-脱氮杂嘌呤脱氧核苷酸(c7dA和c7dG)替代天然嘌呤。这种改进的化学方法允许在迭代切割N端氨基酸的同时,保持用于识别母体多肽的DNA条形码的完整性。每个被切割的氨基酸以稳定的苯氨基硫甲酰(PTC)衍生物形式释放,并共价标记有特定多肽的DNA序列。
在第二阶段,这些带有DNA条形码的PTC氨基酸通过近邻延伸分析(PEA)进行识别。研究人员针对多种PTC修饰的氨基酸和翻译后修饰(PTM)产生了一系列单克隆抗体。当抗体与其目标氨基酸结合时,引物-模板复合物趋于稳定,从而允许DNA聚合酶生成报告分子。该报告分子编码了三个关键信息:氨基酸的身份(通过抗体条形码)、其位置(通过循环特定条形码)以及其来源多肽(通过唯一分子标识符,即UMI)。最后,这些DNA报告分子通过标准的下一代测序(NGS)平台(如Illumina的MiSeq或NovaSeq)进行扩增和读取。
研究人员通过多项概念验证实验展示了该平台的威力。他们实现了模型多肽的准确测序,信号比背景高出20-100倍,并成功区分了仅有一个残基差异的多肽。值得注意的是,该系统展现了六个数量级的动态范围,能以1:1,000,000的比例检测稀有多肽。该平台在PTM图谱绘制方面也表现出色,能够准确识别磷酸化酪氨酸残基的位置,而这正是传统质谱法经常面临的难题。
通过使用UMI对单个多肽分子进行索引,研究实现了真正的单分子测序。通过将极少量的目标多肽掺入“载体蛋白质组”以减少样本损失,团队对数百万个独立分子进行了测序。报告显示,氨基酸分配的平均准确率达到98%,超过91%的读取序列完全无误。尽管仍面临挑战——例如提高C端标记效率和扩大氨基酸特异性抗体库——但这种“逆翻译”框架为全面、高分辨率的从头蛋白质测序提供了一条可扩展的路径,有望彻底改变我们剖析细胞功能状态的能力。